用于阴影检测的DSC特征
论文名称:《用于阴影检测的DSC特征》—2018
论文作者:胡枭玮
毕业院校:香港中文大学
近年主要进展
- scGAN 与 stacked-CNN,分别发表在了 2017 年的 ICCV 与 2016 年的 ECCV 上,主要是通过深度神经网络从大量的数据样本中自动学习特征,用于检测阴影区域
- 缺点:仍然可能将黑色的物体误检为阴影,或者漏掉一些不太明显的阴影区域
spatial context features
- 空间 RNN 获取的空间上下文特征,该特征叫做 spatial context features
- 信息在整张特征图上从左到右传播(公式中的权值 alpha right 是共享的并且可以自动学习的)
- 通过聚合四个方向的结果,对于每一个像素点来讲,就可以获得它所在的行和列的信息
- 进一步方向性的分析空间上下文特征,采用attention 机制,来生成一组权值,并且将他们分成四张权值图,分别通过点对点的方式,乘上四个方向的空间上下文特征
- 在不同方向上选择性的使用空间上下文特征来得到 direction-aware spatial context feature,即 DSC 特征
如何训练网络
- 首先使用卷积神经网络提取不同分辨率下的特征图像(「特征金字塔」)
- 位于低层的特征图像分辨率高,能够提取到图像的细节信息,但是缺乏语义信息
- 位于高层的特征图像分辨率低,可以提取到图像的语义信息,但是缺乏图像细节信息
- 将 DSC 模块应用到每一层特征图上,并将得到的 DSC 特征与原来的特征相连接,然后放大这些特征图像到原图大小
- 放大之后的特征图像组合为 Multi-level integrated features(简称为 MLIF),使用包括 MLIF 特征在内的每一层特征来预测阴影区域
weighted cross entropy loss
- L1 用来平衡阴影区域与非阴影区域的比重,如果阴影区域的面积小于非阴影区域,会惩罚误检的阴影区域多一些
- L2 帮助网络去学习不容易识别的类型(这里主要指阴影或非阴影),如果正确识别的阴影区域较小,那么他的损失函数的权值就会变大,反之亦然
- 使用 MLIF 层以及 fusion 层的均值作为最后的结果。并且使用 CRF 作为后处理,用来改进检测到的阴影区域的边界
shadow-free image
- 先使用网络预测 shadow-free image(去除掉阴影的图像),再接着用 Euclidean loss 训练整个网络
- 对于一组训练样本,我们通过最小化输入图像与 ground truth 非阴影区域的误差,来学习一个颜色转换函数
- 将学到的颜色转换函数应用到原始的 ground truth上,可以得到与输入图像非阴影区域的颜色亮度相匹配的结果
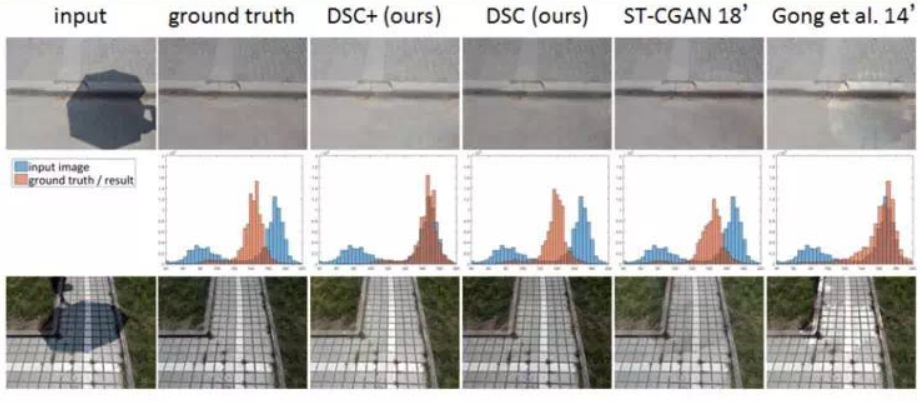
实验效果图
-
阴影检测图
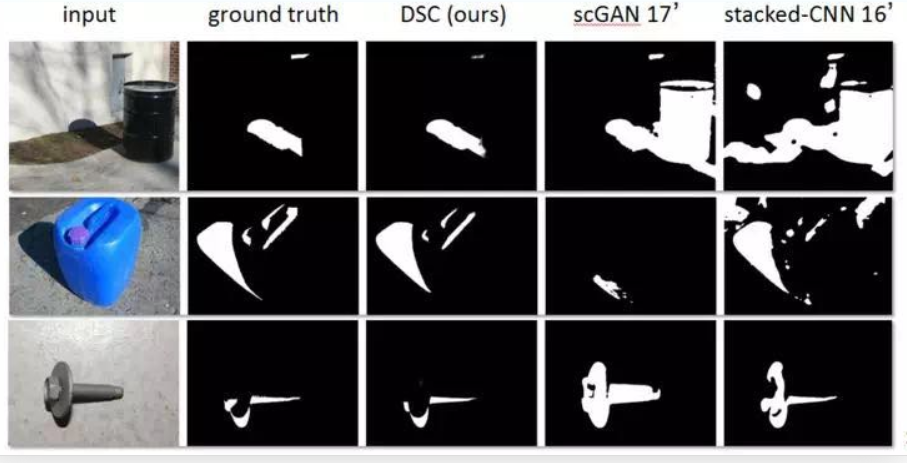
-
阴影去除图