代码整洁之道
书名:《代码整洁之道 Clean Code》
作者:Robert C.Martin
译者:韩磊
总览
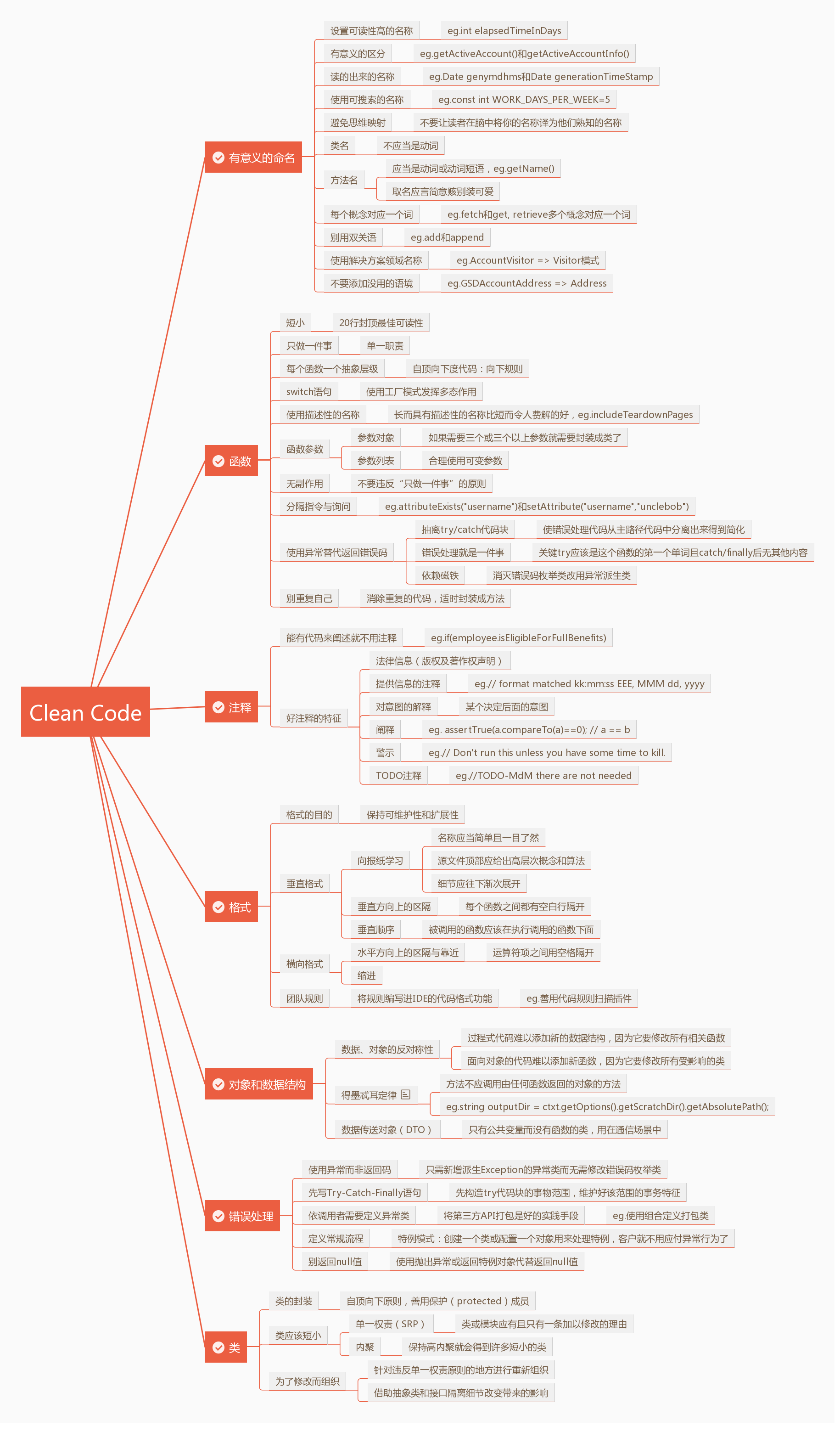
有意义的命名常用规则
-
名副其实
- 代码命名需要花费一定的时间,发现好的命名需要对原来的旧命名进行替换,命名应该表露出的信息:为什么存在,需要做什么事,需要怎么使用。
// 反例 public List<int[]> getThem(){ List<int[]> list1 = new ArrayList<int[]>(); for (int[] x : theList) // theList类型不明确 if (x[0] == 4) // 常量4不知道代表什么,第一个下标也不知道代表什么 list1.add(x); return list1; // 返回的列表怎样使用 } // 正例 public List<int[]> getFlaggedCells(){ List<Cell> flaggedCells = new ArrayList<Cell>(); for (Cell cell : gameBoard) if (cell.ifFlagged()) flaggedCells.add(cell); return flaggedCells; } -
避免误导
- 避免使用开发平台专有的名词,例如sco,aix是UNIX平台的专有名称,使用时会导致意思误会
- 避免对一个数据类型使用错误的数据类型后缀,例如accountList,很容易被误解成一个账号列表
- 避免使用只变换了很小的字母的命名,例如XYZContrillerForEfficientHandlingOfStrings,另一个变量变了其中几个字母,开发过程中极容易混淆两者,尤其是在代码自动补全情况下
-
避免使用小写字母l和大写字母O作为变量,很像数字1和0,易引起误会
-
做有意义的区分
- 不使用拼写错误的单词,如果发现单词已经拼写错误尽可能修改
- 保持名称相异,避免使用纯字母数字这种无法提供具体意图的命名,例如:a1,a2,aN
- 避免没有意义的区分,例如ProductInfo与ProductData,info与data意义无区别,类似于a,the
-
使用可以读的出来的单词
- 避免自造词,例如modymdhms与modificationTimetamp
- 避免使用非常规缩写
-
使用可以搜索的名称
- 例如WORK_DAYS_PER_WEEK可以检索到有限的结果,但是例如7或者e这样的量检索结果将很多,as
-
避免使用编码
- 在使用一门语言时没有必要增加新的编码,名称达意即可,否则增加阅读负担
- 没必要的前缀,例如前缀m_xxx表明成员变量,实际上前缀m没有必要,i_
- 前导字母,例如单词前使用大写I或者C表示接口,直接实现更好,避免增加阅读负担
-
避免思维映射
- 在某些专业术语中,避免将某些词翻译成熟悉的词
- 循环语句中避免使用单字母,否则引起不必要的误解
-
类名与对象名
- 名词或者名词短语,不应该是动词
- 使用类似于Customer,WikiPage,Account,AddressParser,避免使用类似于Manager、Data、Info等通用名词
-
方法名
- 动词或者动词短语,例如postPayment、deletePage、save等
-
避免使用花里胡哨的词
- 避免使用诸如某些典故或者某些梗的词,应该使用常用理解词,例如HolyHandGrenade与deleteItems
-
每个概念对应一个词
- 例如fetch,retrieve,get混合使用,很难清楚是哪种规范与风格
- 名词中例如controller、manager,driver,应该保持一以贯之原则
-
避免使用双关语
- 例如add表示增加,如果是加入到某个集合中,应该使用append
- 直译并且表示其确切的意义,避免学院派模式
-
使用领域的专业术语
- 例如计算机科学ComputerScience
- 软件设计模式中表达访问者,惯用名词AccountVisitor
- 使用源自问题领域的名称
-
添加有意义的语境
- 例如一个集合变量firstName,lastName,state明显没有addrFirstName,addrLastName,addrState意义明确
-
不要添加没有意义的语境
- 例如在项目GSD中增加邮件地址类,使用GSDAccountAddress,前10个字母明显多余而且与当前语境无关
函数
-
短小
- 函数应该精简,显示不要超过屏幕宽度,长度不应过长而换页查看(除非必要)
- 缩紧层级不该多于两层,便于阅读理解
-
只做一件事
- 函数应该只做一件事
- 判断函数是否做了不止一件事,就是看是否可以再拆出一个函数
-
每个函数一个抽象层级
- 函数中的语句都要在同一个抽象层级上,即基础概念还是细节
- 向下原则,自顶向下保持抽象层级进行阅读
-
switch语句
- switch短小很难,而且增加新的类型时无法只做一件事,一般使用工厂模式代替
- python中没有switch结构
-
使用描述性名称
- 虽然函数应该保持短小,但是函数名长一点没有问题
- 花很多时间想一下函数需要做的事情是有意义的,利于重构和阅读
-
函数参数
- 理想的参数数量为0时最佳,尽量避免三个以上的参数,覆盖测试参数越多越难,而且难以使用
// 反例,分页查询订单 6个参数 Public Page<Order> queryOrderByPage(Integer current,Integer size,String productName,Integer userId,Date startTime,Date endTime,Bigdecimal minAmount ,Bigdecimal maxAmount) { } // 正例 @Getter @Setter Public class OrderQueryDTO extends PageDTO { private String productName; private Integer userId; private Date startTime; private Date endTime; private Bigdecimal minAmount ; private Bigdecimal maxAmount; } // 分页查询订单 6个参数 Public Page<Order> queryOrderByPage(OrderQueryDTO orderQueryDTO) { } -
无副作用
- 例如一个函数返回结果为True与False,是否会有其他结果而导致bug
- 检查密码并且初始化session的方法 命名为checkPasswordAndInitializeSession而非checkPassword,副作用产生,实际上是违反单一职责原则
- 避免使用输出函数,如果需要修改某个对象的数据,最好使用方法调用,例如appendFooter(report)不如report.appendFooter()
-
设置(写)和查询(读)分离
- 例如if(set(“username”, “unclebob”)) { … } 的含义模糊不清。应该改为if (attributeExists(“username”)) { setAttribute(“username”, “unclebob”); … },实际上set(“username”, “unclebob”)做了两件事
-
使用异常代替返回错误码
- 返回错误码会要求调用者立刻处理错误,从而引起深层次的嵌套结构,就是异常需要再判读处理
- 使用异常机制代替返回错误码,错误码就可以从主路径代码中抽离出来
// 反例 if (deletePate(page) == E_OK) { if (xxx == E_OK) { if (yyy == E_OK) { log; } else { log; } } else { log; } } else { log; } // 正例 try { deletePage; xxx; yyy; } catch (Exception e) { log(e->getMessage(); } -
抽离try/catch模块
- 错误处理与正常流程很容易被try/catch搞混,所以将正常流程与错误处理抽离出来更清晰 try{ do; } catch(Exception e) { handle; }
- 错误处理应该只做一件事,只是处理当前错误,不应该有其他内容
-
不能重复 **
- 重复是软件中一切邪恶的根源。当算法改变时需要修改多处地方
- 避免重复诸如设置配置文件,使用utils工具模块进行封装
-
结构化编程
- 只要函数保持短小,偶尔出现的return、break、continue语句没有坏处,甚至还比单入单出原则更具有表达力
- goto只有在大函数里才有道理,应该尽量避免使用
-
如何写出这样的函数
- 并不需要一开始就按照这些规则写函数,在最开始编程时没人做得到。
- 想些什么就写什么,然后再逐渐打磨这些代码,并且按照这些规则组装函数。
注释
-
注释基本原则
- 若编程语言足够有表现力,符合语言阅读姿势,实际上就不需要注释。
- 注释可能并没有起到好作用,代码在演化,注释却不总是随之变动,不准确的注释比没注释坏的多。
-
用代码来阐述
- 创建一个与注释所言同一事物的函数即可
// check to see if the employee is eligible for full benefits // 反例 if ((employee.falgs & HOURLY_FLAG) && (employee.age > 65)) // 正例 if (employee.isEligibleForFullBenefits) -
好注释
- 具有法律信息,即版权著作声明
- 提供基本信息,如解释某个抽象方法的返回值和函数用法作用 def xxx():
- 对意图的解释,反应了作者做出某个决定或者完成某段逻辑后面的意图,放大 一些看似不合理之物的重要性,解释为什么需要这样做
- 把某些晦涩的参数或者返回值的意义翻译成可读的形式,更好的方法是让它们自身变得足够清晰,但是类似标准库的代码是无法修改的
- 警示,警告为什么要这样做或者不要这样做
- **TODO注释,解释这块代码为什么没有作用,未来需要怎么用,注无用代码需要删除
# python 常用头部信息
# -*- coding: utf-8 -*-
# *****************************************************
# title : xxx
# description : xxxxxx
# author : xxx
# email : xxx@xxx
# date : xxxx-xx-xx
# version : xxx
# usage : xxx
# notes : xxx
# version : xxx
# python_version : x.x.x
# *****************************************************
-
坏注释
- 自言自语,花费太多的时间写没有用处的注释
- 多余的注释,把逻辑在注释里写一遍不能比代码提供更多信息,读它不比读代码简单,一目了然的成员变量别加注释,显得很多余,例如:这是一个加法运算 +
- 误导性注释吗,使调试时进入误区,误导方向
- 遵循规矩的注释,每个函数都加注释,每个变量都加注释
- 日志式注释,有了代码版本控制工具,不必在文件开头维护修改时间、修改人这类日志式的注释 svn git
// 反例
// does the module from the global list <mod> depend on the
// subsystem we are part of?
if (smodule.getDependSubsystems.contains(subSysMod.getSubSystem)
// 正例
ArrayList moduleDependees = smodule.getDependSubsystems;
String ourSubSystem = subSysMod.getSubSystem;
if (moduleDependees.contains(ourSubSystem))
- 位置标记,标记多了会被我们忽略掉,例如很多注释 ///////////////////// Actions //////////////////////////
- 署名 /* add by rick */ 源代码控制工具控制,署名注释没有必要。
- 注释掉的代码,会导致看到这段代码其他人不敢删除,删除或者TODO
- 信息过多,别在注释中添加历史话题或者无关的细节,前n个版本不会再用了
- ** 没解释清楚的注释,注释的作用是解释未能自行解释的代码,如果注释本身还需要解释就没有必要了
- 短函数的函数头注释,为短函数选个好名字比函数头注释要好
格式(IDE插件均有效支持)
- 垂直格式
- 短文件比长文件更易于理解,平均200行,最多不超过500行的单个文件可以更加明晰(存疑)
- 区隔,封包声明、导入声明、每个函数之间,都用空白行分隔开,空白行下面标识着新的独立概念
- 靠近,紧密相关的代码应该互相靠近,例如一个类里的属性之间别用空白行隔开
- 变量声明应尽可能靠近其使用位置,循环中的控制变量应该总是在循环语句中声明。
- 成员变量应该放在类的顶部声明,不要四处放置
- 如果某个函数调用了另外一个,就应该把它们放在一起,调用者尽可能放在被调用者之上
- 执行同一基础任务的几个函数应该放在一起
- 水平格式 vim
- 一行代码不必死守80字符的上限,偶尔到达100字符不超过120字符即可
- 区隔与靠近,空格强调左右两边的分割,赋值运算符两边加空格,函数名与左圆括号之间不加空格,乘法运算符在与加减法运算符组合时不用加空格
- 不必水平对齐,例如声明一堆成员变量时,各行不用每一个单词都对齐
- 短小的if、while、函数里最好也不要违反缩进规则,不要这样if (xx == yy) z = 1;写作一行,虽然缩进后是比较难看
对象和数据结构
- 对象与数据结构的反对称性
- 使用数据结构便于在不改动现在数据结构的前提下添加新函数,使用对象便于在不改动既有函数的前提下添加新类
- 使用数据结构难以添加新数据结构,因为必须修改所有函数,使用对象难以添加新函数,因为必须修改所有类。
- 万物皆对象并不准确,有时候也会在简单数据结构上做一些过程式的操作
- Demeter定律(最少知识原则)
- 模块不应该了解它所操作对象的内部情形,即没有必要受内部逻辑影响,封装性
- class的方法只应该调用类本身方法,方法创建的对象,作为参数传递的方法,类所持有的对象
- 方法不应调用由任何函数返回的对象的方法,final String outputDir = ctxt.getOptions.getScratchDir.getAbsolutePath();
- 一个简单例子是,人可以命令一条狗行走,但是不应该直接指挥狗的腿行走,应该由狗去指挥控制它的腿如何行走
错误处理
-
使用异常而不是返回错误码,TF
- 如果使用错误码,调用者必须在函数返回时立刻处理错误,但这很容易被忘记
- 错误码通常会导致嵌套判断,使代码结构不严谨
-
先写try-catch-finally语句
- 当编写可能会抛异常的代码时,先写好try-catch-finally再往里堆逻辑
-
在catch里尽可能的记录错误信息,记录失败的操作以及失败的类型,(日志非常重要!!!)
-
根据调用者的需要定义不同的异常处理类
- 同一个try里catch多个不同exception,但是catch处理的事(打日志等)是一致的,可以考虑用函数打包一下这个异常处理,针对不同异常仅需throw成同一个异常而不做任何处理,在外层catch时统一处理(打日志等)。如果仅想捕获一部分异常而放过其他异常,就使用不同的函数打包这个异常处理
-
特例模式:,创建一个类来处理特例
// 反例 try{ MealExpendses expenses = expenseRepotDAO.getMeals(employee.getID); m_total += expenses.getTotal; // 如果消耗了餐食,计入总额 } catch(MealExpensesNotFound e) { m_total += getMealPeDiem; // 如果没消耗,将员工补贴计入总额 } // 断了业务逻辑。可以在getMeals里不抛异常, // 没消耗餐食的时候返回一个特殊的MealExpense对象erdiemMealExpense),复写getTotal方法。 // 正例 MealExpendses expenses = expenseRepotDAO.getMeals(employee.getID); m_total += expenses.getTotal; publc classPerDiemMealExpensesimplementsMealExpenses{ publicintgetTotal{ //return xxx; //返回员工补贴 } } -
别返回null值
- 返回null值只要一处没检查null,应用程序就会失败,一般调用处也没有进行空值处理
- 当想返回null值的时候,可以试试抛出异常,或者返回特例模式的对象
-
别传递null值
- 在方法中传递null值是一种很危险的做法,应该尽量避免
- 在方法里用if或assert过滤null值参数,但是还是会出现运行时错误,没有良好的办法对付调动者意外传入的null值,恰当的做法就是禁止传入null值
边界(将第三方代码干净利落地整合进自己的代码中)
-
使用第三方代码
- 避免公共API返回边界接口,或者将边界接口作为参数传递给API,将边界保留在近亲类中
- 不要再生产代码中试验新东西,编写测试来理解第三方代码
- 避免我们的代码过多地了解第三方代码中的特定信息
- 单元测试TDD三定律
序号 定律 1 在编写不能通过的单元测试前,不可编写生产代码。 2 只可编写刚好无法通过的单元测试,不能编译也算不过。 3 只可编写刚好足以通过当前失败测试的生产代码。 -
保持测试整洁
- 脏测试等同于没测试,测试代码越脏生产代码越难修改
- 测试代码和生产代码一样重要
- 整洁的测试代码最应具有的要素是:整洁性,测试代码中不要有大量重复代码的调用
-
每个测试一个断言
-
断言用于判断一个表达式,在表达式条件为 false 的时候触发异常
- 每个测试函数有且仅有一个断言语句
- 每个测试函数中只测试一个概念
-
-
整洁的测试依赖于FIRST规则
- fast: 测试代码应该能够快速运行,因为我们需要频繁运行它
- independent: 测试应该相互独立,某个测试不应该依赖上一个测试的结果,测试可以以任何顺序进行
- repeatable: 测试应可以在任何环境中通过
- self-validating: 测试应该有bool值输出,不应通过查看日志来确认测试结果,不应手工对比两个文本文件确认测试结果
- timely: 及时编写测试代码,单元测试应该在生产代码之前编写,否则生产代码会变得难以测试
类
- 类的结构组织
- 公共静态常量,私有静态变量,私有实体变量,公共函数,私有工具函数
- 类应该短小
- 对于函数我们计算代码行数衡量大小,对于类我们使用权责来衡量
- 类的名称应当描述其权责,类的命名是判断类长度的第一个手段,如果无法为某个类命以准确的名称,这个类就太长了,类名包含模糊的词汇,如Processor、Manager、Super,这种现象就说明有不恰当的权责聚集情况
- 单一权责原则: 类或者模块应该有一个权责,即只有一条修改的理由
- 系统应该由许多短小的类而不是少量巨大的类组成
- 类应该只有少量的实体变量,如果一个类中每个实体变量都被每个方法所使用,则说明该类具有最大的内聚性,创建最大化的内聚类不太现实,但是应该以高内聚为目标,内聚性越高说明类中的方法和变量互相依赖、互相结合形成一个逻辑整体
- 保持内聚性就会得到许多短小的类,如果把一个大函数的某一小部分拆解成单独的函数,拆解出的函数使用了大函数中的4个变量,不必将4个变量作为参数传递到新函数里,仅需将这4个变量提升为大函数所在类的实体变量,但是这么做却因为实体变量的增多而丧失了类的内聚性,更好多做法是让这4个变量拆出来,拥有自己的类,将大函数拆解成小函数往往是将类拆分为小类的时机
- 为修改而组织
- 类应当对扩展开放,对修改封闭,即开放闭合原则
- 在理想系统中,通过扩展系统而非修改现有代码来添加新特性,(可惜往往做不到)
系统
- 将系统的构造与使用分开
- **如果所有对象都已经正确构造,则将全部构造过程搬迁到main或者被称之为main的模块中
- 有时应用程序也需要负责确定何时创建对象,我们可以使用抽象工厂模式让应用自行控制何时创建对象,但构造能力在工厂实现类里,与使用部分分开
- 依赖注入(DI):由容器动态的将某个依赖关系注入到组件之中,控制反转(IoC):Ioc意味着将你设计好的对象交给容器控制,而不是传统的在你的对象内部直接控制,这两个是分离构造与使用的强大机制(java机制,可拓展理解到其他语言)
迭进
-
运行所有测试
- 紧耦合的代码难以编写测试,测试写的越多,就越会遵循依赖注入之类的规则,使代码加减少耦合
- 测试消除了对清理代码就会破坏代码的恐惧
-
消除重复
- 两个方法提取共性到新方法中,新方法分解到另外的类里,从而提升其可见性。
- 模板方法模式是消除重复的通用技巧
// 原始逻辑 public class VacationPolicy { public void accrueUSDivisionVacation { //do x; //do US y; //do z; } public void accrueEUDivisionVacation { //do x; //do EU y; //do z; } } // 模板方法模式重构之后 abstract public class VacationPolicy { public void accrueVacation { x; y; z; } private void x { //do x; } abstract protected void y { } private void z { //do z; } } public class USVacationPolicy extends VacationPolicy { protected void y { //do US y; } } public class EUVacationPolicy extends VacationPolicy { protected void y { //do EU y; } } -
表达意图
- 作者把代码写的越清晰,其他人理解代码就越快
- 太多时候我们深入于要解决的问题中,写出能工作的代码之后,就转移到下一个问题上,没有下足功夫调整代码让后来者易于阅读,花一点点时间在每个函数和类上
-
尽可能少的类和方法
- 为了保持类和函数的短小,可能会早出太多细小的类和方法
- 类和方法数量太多,有时是由毫无意义的教条主义导致的
-
防御并发代码问题的原则与技巧
- 遵循单一职责原则,分离并发代码与非并发代码
- 限制临界区数量,限制对共享数据的访问
- 避免使用共享数据,使用对象的副本
- 线程尽可能地独立,不与其他线程共享数据
附录(本文所涉及的其他学习资料)
- 命名法:
- 小驼峰法:第一个单词以小写字母开始;第二个单词的首字母大写或每一个单词的首字母都采用大写字母,例如:myFirstName、myLastName
- 大驼峰法(帕斯卡命名法):相比小驼峰法,大驼峰法把第一个单词的首字母也大写了
- 下划线法命名:函数名中的每一个逻辑断点都有一个下划线来标记(python推荐)
- 匈牙利命名法:变量名=属性+类型+对象描述(不推荐)
-
python的Google代码风格规范
- https://zh-google-styleguide.readthedocs.io/en/latest/google-python-styleguide/python_language_rules/
-
软件模式设计
- 《Head First设计模式》
- 《大话设计模式》
-
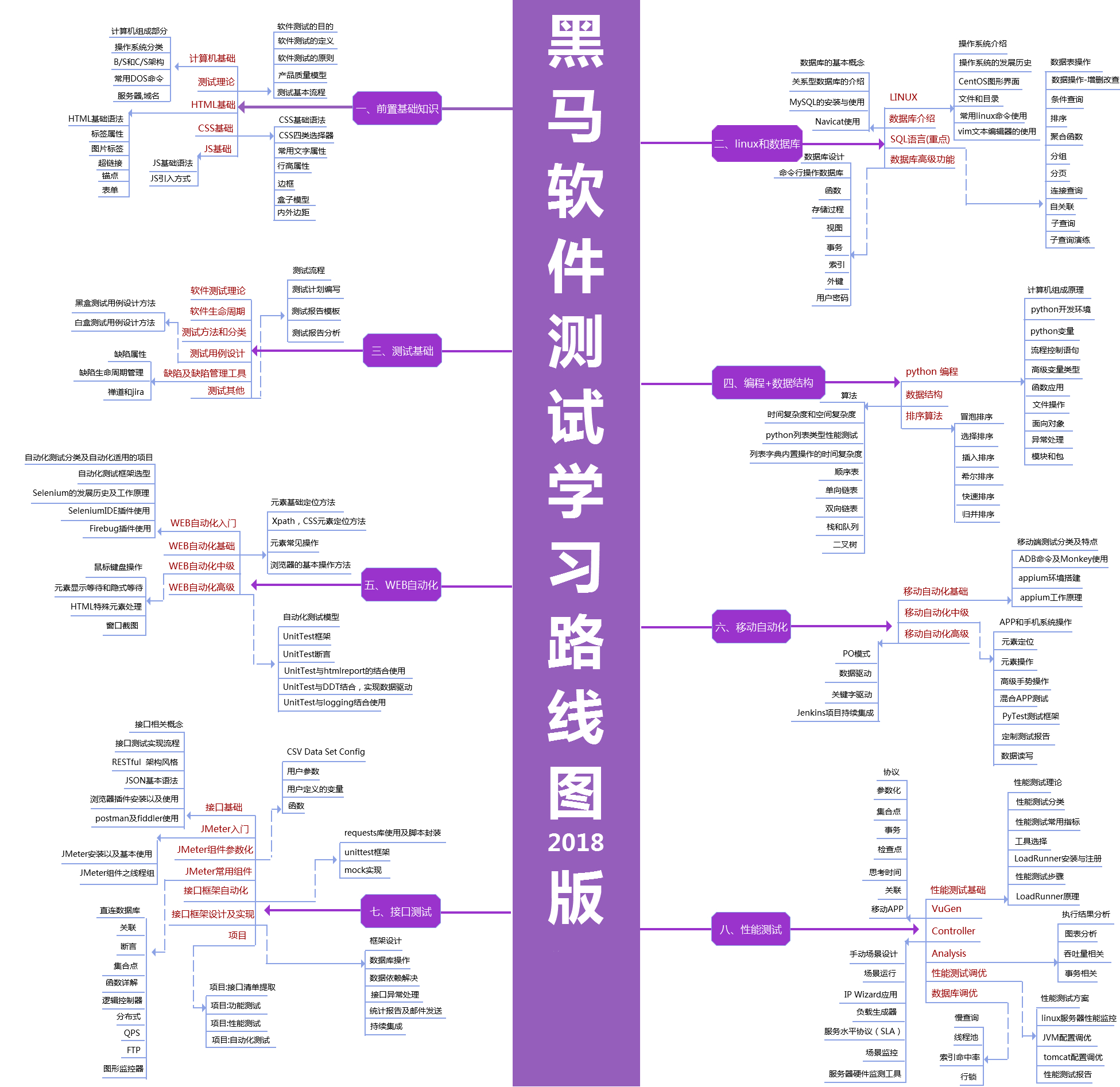
软件测试(注:转自黑马测试开发教程)